“경제성의 원리”라고도 불리우는 오컴의면도날과 같이 통계학적 모델링도 마찬가지이다. 어떤 현상을 설명할 때 불필요한 가정을 해서는 안 된다는 것. 고로 똑같은 성능을 내는 모델이라면, 단순하면 단순할수록 좋다. 이 원칙에 의거해 ( 분석자마다 원칙은 다를 수 있다. 적어도 나는 이러한 원칙을 항상 마음에 새기고 있을 뿐이다. ) 분석을 하기 전 고려해야할 사항들은 아래와 같을 것이다.
- How many features do you have ? ( to build your model )
- How much score do you want ? ( to explain your model )
- How can you test your model ? ( for generalization )
WORKFLOW OF REGRESSION
DEFINE DATASET
- Sample set
- Train set
- Validation set
- Test set
DEFINE FEATURES
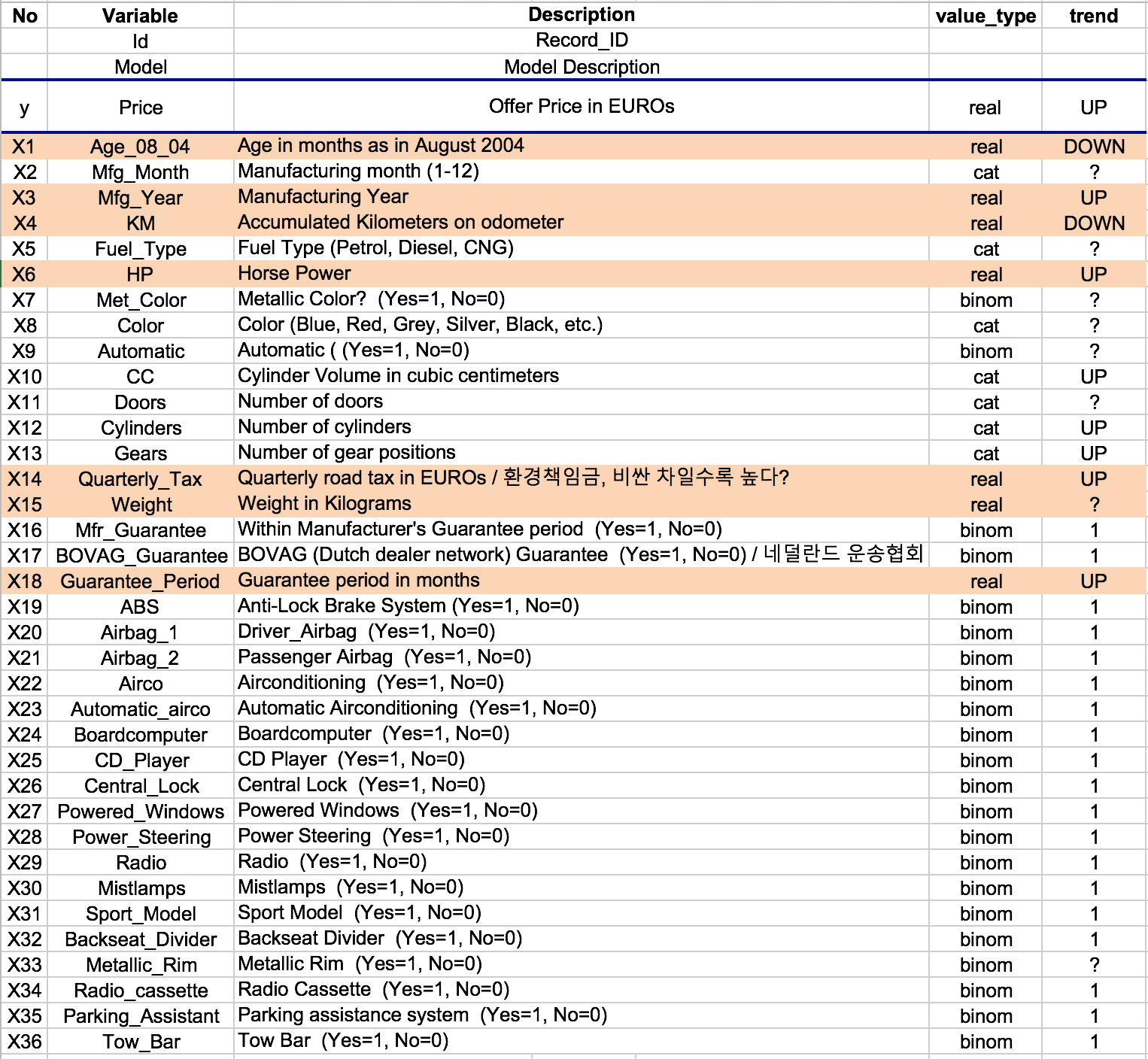
EXPLORE FEATURES
회귀분석 모형에 사용할 변수를 찾아가는 과정.
주로 시각화 + Descriptive statistics(기술통계)를 통해 갖고있는 데이터 분포 및 특징(평균, 최빈값, 중앙값, 분산, 최대값, 최소값 등)을 파악한다. 이를 통해 모형을 설명 할 변수들의 중요도를 대략적으로 파악 할 수 있다. 또한 수많은 변수들 중에서 회귀모형에 사용 할 초기 변수들을 선택하는데 어느정도 기준을 세울 수 있다.
- 각각의 변수 별 경험적 결과가 어떠한지 정의하기
- 분포 파악하기
- real value : 종속변수 ( ) 와 설명변수 ( ) 간의 Scatter plot ( 또는 Pair plot ) + 상관계수 파악을 통해 상관정도를 가늠
- categorical value : 설명변수의 등급별 종속변수 값의 Box plot + Paired Sample t-test 를 통해 유의한 차이가 있는지 파악
FEATURE SELECTION ( STEP-WISE METHODS )
OUTLIERS AND INFLUENTIAL OBSERVATIONS
이상치 ( Outlier ) 는 데이터 분포에서 극단에 있는 Data point 를 말한다. 이상치가 있고, 없고에 따라 분포의 특성 ( 평균 ) 이 급격하게 움직이는데, 이러한 Data point 는 내가 갖고있는 데이터의 대표값에 나쁜 영향 ( Influential 이 강함 ) 을 주는 것이다. 반면에 대표값에 별다른 영향을 주지 않는다면 ( Inlfuence 가 약함 ) 해당 Data point 를 그대로 사용해도 무방하다.
- Leverage : 설명변수 값에 대한 이상치 파악
- ( Studentized ) Residual : 종속변수 값에 대한 이상치 파악
- DFFITS : 추정치 ( ) 에 대한 영향력 평가
- COOK’S DISTANCE : 회귀계수에 대한 종합적 영향력 평가
DIAGNOSIS OF MODELS AND ASSUMPTIONS
- 선형성 검토 : 독립변수에 대한 잔차를 통해 선형여부를 판단 ( 를 대수변환, 지수변환 등 )
- 등분산성 검토 : 에 대한 잔차를 통해 등분산성 판단 ( 를 대수변환, 제곱근변환 등 )
- 독립성 검토 : 오차항들은 서로 독립
CHECK AN IMPROVED MODEL
DIAGNOSIS OF MULTICOLLINEARITY
독립변수 ( ) 들 간에 서로 상관성이 높을 경우 Multicollinearity ( 다중공선성 ) 이 발생한다. 머신러닝 문제에서 Overfitting 과 비슷한 개념. 이 경우, 모델에 학습되지 않은 범위의 데이터가 들어올 경우 굉장히 불안정한 예측값 ( ) 을 내놓는다. 모델링의 목적인 Generalization 에 위배.
- ( Pearson ) 상관행렬 및 상관계수를 통해 독립변수간 상관성 파악
- 고유값 ( Eigen value ) < & 분산팽창계수 ( VIF; Variance Inflation Factor ) < 검토